Ser parte de LIDSoL me ha permitido conocer y colaborar con otras comunidades que hacen un trabajo estupendo.
Comunidad Elotl es una de ellas.
Elotl es un proyecto colaborativo, sin fines de lucro, dedicado a la creación de herramientas digitales libres (obvio :heart:) y gratuitas con el objetivo de preservar y difundir lenguas indígenas mexicanas. Además, buscan promover este tema en la agenda nacional y realizar investigaciones académicas en ese sentido.
El tema central de Elotl es la
diversidad lingüística y la creación de tecnología para toda esta diversidad. México cuenta con 11 grupos de lenguas desglosadas en 68 lenguas distintas y que a su vez engloban 364 variantes (casi una variante por día del año 😲).
¿Qué es Esquite?
Además de ser un vaso con deliciosos elotes desgranados, mayonesa, queso y chile (del que pica) es uno de los proyectos con los que LIDSoL ha colaborado.
Esquite es un
framework de software libre destinado a personas que poseen corpus paralelos (textos bilingües) y que desean tener un sistema web que les permita subir, administrar realizar búsquedas de palabras o frases en sus corpus.
El software está hecho en
django (otro
framework para desarrollo web escrito en
python 🐍) y utiliza
elasticsearch como motor de búsquedas y gestión de documentos.
Un ejemplo de uso del
framework es el corpus paralelo
TSU̱NKUA que permite consultar documentos bilingües digitalizados y alineados de distintas variantes del otomí. Al día de la publicación de esta entrada el corpus cuenta con aproximadamente
5519 líneas paralelas de
6 documentos distintos.
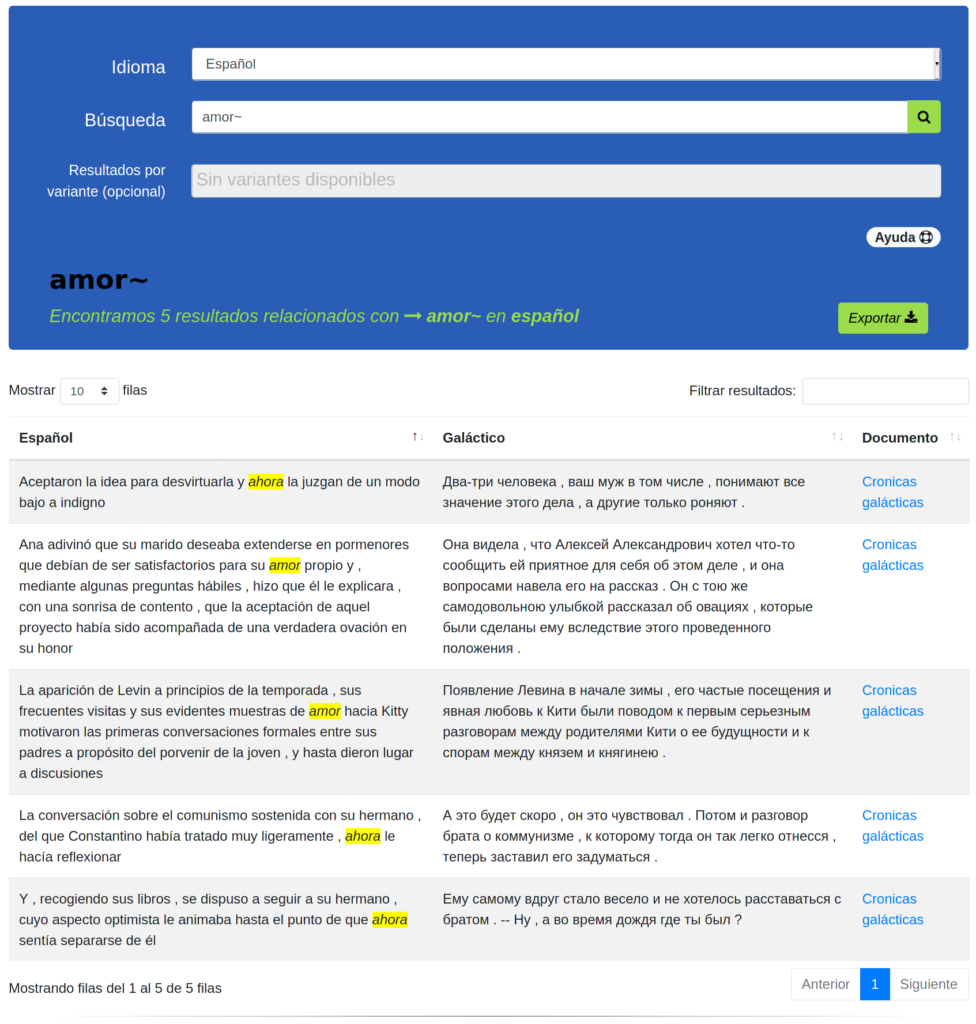
Para enriquecer las búsquedas la plataforma web cuenta con un filtrado por variante dialectal. Además, el motor de búsqueda permite realizar operaciones especiales para la realización de búsquedas avanzadas. Algunos operadores son los que se listan a continuación:
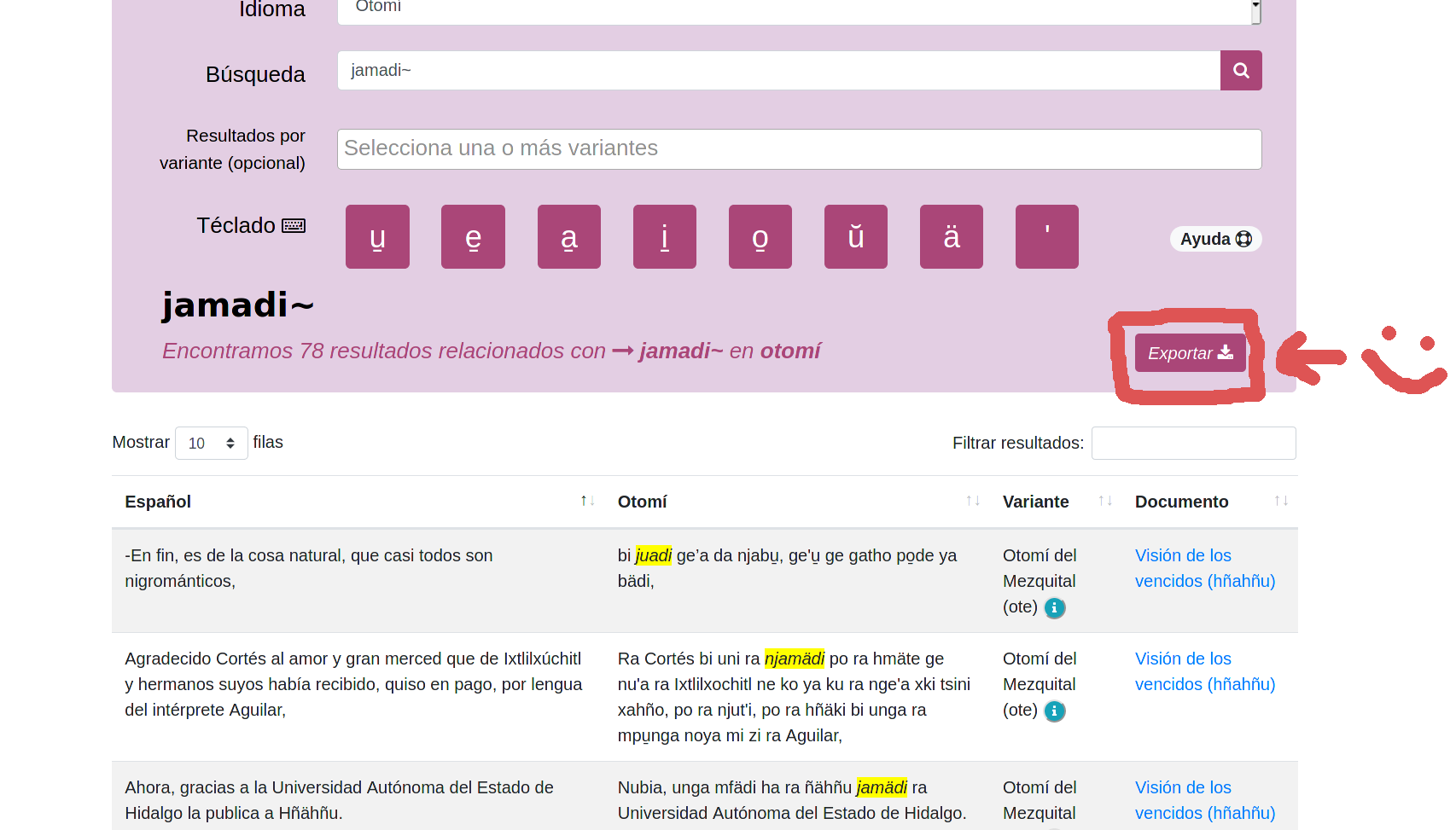
- Búsqueda difusa(
~): Incluye en los resultados las palabras con similitud ortográfica. Por ejemplo si se busca:jamadi~ los resultados incluirán las palabras jämadi, dabadi, juadi, jamfri, etcétera.
- Comodín(
*): Reemplaza cero o más caracteres. Por ejemplo: mexic*
- Comodín(
?): Reemplaza un carácter. Por ejemplo: nin?s
Una característica especialmente pensada para las personas que estén interesadas en la investigación o que deseen hacer experimentos con los resultados las búsquedas que realicen se pone a disposición de las usuarias la posibilidad de exportar los resultados en formato.
.csv Para mayor información pueden checar la
sección de ayuda de la página.
Me convenciste, dame 2
Bueno, ya que insisten, vamos a ver que necesitamos para instalar nuestro flamante
framework de corpus paralelos. Los programas que debes tener instalados son los siguientes:
Dependencias
gitpython3.6 o una versión más actual
virtualenv: entornos virtuales para paquetes de python
elasticsearch 7.6 o mayor
Instalación
0. Instalamos y corremos elasticsearch
Puedes consultar la
página oficial de Elasticsearch para completar este paso
user@machine:~$ git clone https://github.com/ElotlMX/Esquite.git
2. Preparando el entorno
Entramos al directorio de Esquite, creamos el entorno virtual y lo activamos
user@machine:~$ cd Esquite/
user@machine:~/Esquite$ virtualenv env
user@machine:~/Esquite$ source env/bin/activate
3. Instalación de dependencias
(env)user@machine:~/Esquite$ pip install -r requeriments.txt
4. Asistente de configuración 💫
El proyecto requiere de un archivo de configuración. Este archivo es creado de forma automática con un asistente que utiliza
Deep Learning (broma). Ejecutamos el asistente con el siguiente comando:
(env)user@machine:~/Esquite$ python wizard.py
El asistente pedirá una serie de detalles para la plataforma como el nombre de la organización que la mantendrá, nombre del proyecto, la primera y segunda lengua del corpus, etcétera. La configuración se verá de esta manera:
Asistente de configuración del backend 🧙
Nombre de la organización>> LIDSoL
Nombre del proyecto>> Galagar
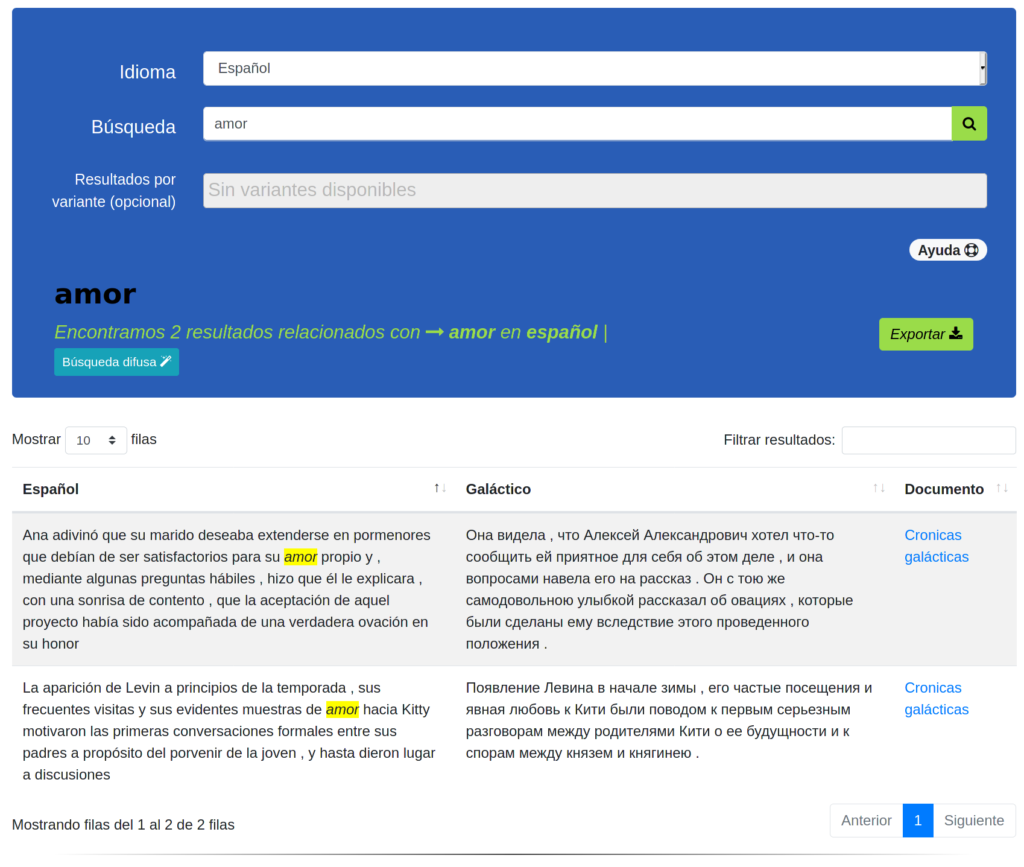
Primera lengua del corpus (l1)>> español
Segunda lengua del corpus (l2)>> galáctico
Generando token secreto
⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙
🛑 El corpus requiere que exista un indice de
Elasticsearch con las configuraciones que se indican
en la documentación 🛑
⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙⚙
Índice de Elasticsearch>> galagar
Protocolo HTTP o HTTPS [http]>>
Nombre o IP del servidor de Elasticsearch [localhost]>>
Puerto del servidor de Elasticsearch [9200]>>
Token Google Analytics (OPCIONAL)>>
Colores del proyecto (HEXADECIMALES)
Primario [#ffffff]>>#295db6
Secundario [#000000]>>#9adc49
Generando archivo para la configuración:
{'ALT_TEXT': '#000000',
'COLABS': [],
'DEBUG': 'False',
'GOOGLE_ANALYTICS': '',
'INDEX': 'galagar',
'KEYBOARD': [],
'L1': 'Español',
'L2': 'Galáctico',
'NAME': 'GALAGAR',
'ORG_NAME': 'LIDSOL',
'PRIMARY_COLOR': '#295db6',
'SECONDARY_COLOR': '#9adc49',
'SECRET_KEY': '<secreto>',
'SOCIAL': {'blog': '',
'email': '',
'facebook': '',
'github': '',
'site': '',
'twitter': ''},
'TEXT_COLOR': '#ffffff',
'URL': 'http://localhost:9200/'}
Terminado :)
El asistente menciona que debemos tener un índice de
elasticsearch creado para que funcione correctamente nuestra plataforma web. Para crear el índice con las configuraciones necesarias ejecutamos esta línea de código:
$ curl -X PUT -H "Content-Type: application/json" -d @elastic-config.json localhost:9200/<nombre-de-tu-indice>
6. Corremos la aplicación
(env)user@machine:~/Esquite$ python manage.py runserver
Listo, si vamos a nuestro navegador a la dirección
localhost:8000/ deberíamos ver algo como esto:

Se pueden realizar algunas personalizaciones como los colores de la página, colaboradorxs del proyecto, ligas a las redes sociales y el banner de la página (que por cierto modificamos para este ejemplo). La personalización la abordaremos a detalle en otra entrada ;)
Administración
El sistema cuenta con un administrador de documentos en la dirección
localhost:8000/corpus-admin/ donde podemos agregar nuevos documentos, visualizarlos, agregar nuevas líneas a un documento previo y eliminarlos. Además, podemos ver las variantes presentes en el corpus y hacer una copia de seguridad en formato.
csv

Esto se ve triste porque nuestro sistema está vacío. Debemos alimentarlo con textos paralelos :book:.
Aliméntame humano 🤖

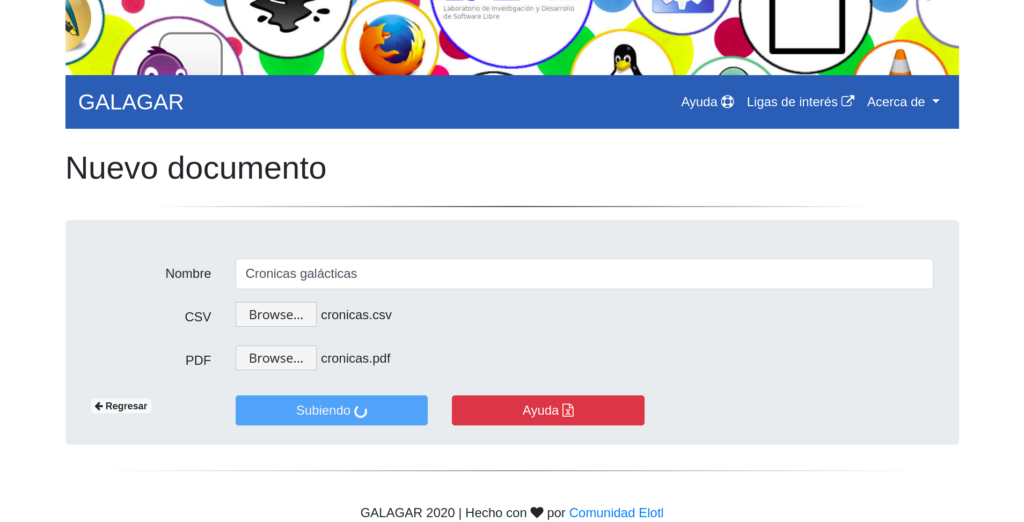
Damos clic en “Nuevo Documento”, agregamos el nombre del documento, el archivo
csv con nuestro corpus alineado y un archivo
pdf asociado a nuestro documento. El formato de los archivos
csv es la siguiente:
| Una vez una señora se emborrachó |
xu̱tu̱ bimáyóhthó ’á ngŭ ra bésíno |
Otomí del Estado de México (ots) |
| Luego se fue a dormir a la casa del vecino |
nándi na ra t’u̱xú bintí |
Otomí del Estado de México (ots) |
| Después que se durmió |
despwés ya biyóbí |
Otomí del Estado de México (ots) |
El archivo tiene una cabecera. La primera columna es texto en español, la siguiente columna será la segunda lengua (en este ejemplo otomí) y la tercera columna es la variante (si esta está disponible).

Probemos
Conclusiones
- Este framework al ser software libre les permite ver, modificar, estudiar y redistribuir sus modificaciones al código fuente. Este código se encuentra en el repositorio antes mencionado.
- Si les gusta programar y les interesan las tecnologías aplicadas al lenguaje la Comunidad Elotl está abierta a que puedan contribuir con el desarrollo de esta y otras plataformas. Manden sus Pull Requests :D
- Si no les gusta programar o no es su área de estudio aún pueden colaborar con la comunidad haciendo:
- Investigación 🔬: Algunos integrantes de la Comunidad Elotl tienen posibilidad de dirigir o asesorar tesis, principalmente dentro de la UNAM
- Difusión 📡: comparte información relevante con la comunidad para que sea difundida
- Donaciones 🎁: todas las herramientas son gratuitas y para poder continuar con los desarrollos la Comunidad está constantemente búsqueda de donativos.
- Pueden checar todas las opciones de colaboración en esta liga.
Fuente: LIDSoL

Recent Comments
No comments added yet.