En Comunidad Elotl nos dedicamos al desarrollo de recursos digitales y tecnologías del lenguaje para las diversas lenguas habladas en México. Estas lenguas tienen una gran variación dialectal, ortográfica y de otros tipos. En esta entrada de blog platicamos sobre algunas cuestiones a las que nos hemos enfrentado al tratar textos en otomí
Se le llama otomí* a un conjunto de lenguas de la rama otopame (de la familia lingüística otomangue), las cuales se hablan en ocho estados de la República Mexicana (Lastra, 1996: 361); estos estados son Guanajuato, Querétaro, Hidalgo, Puebla, Veracruz, Michoacán, Tlaxcala y México. Dada la diversidad de lugares en que se habla alguna lengua otomí, la variedad interna de las lenguas otomíes es muy vasta.
Tomar en cuenta la variación de una lengua es importante para poder procesar los textos por medio de técnicas computacionales y, eventualmente, realizar tecnologías del lenguaje. Sobretodo si estas variaciones implican diferentes ortografías dependiendo de la región donde se hable.
En vista de lo anterior, nuestro primer paso fue identificar que, de acuerdo con Lastra (2001), existen nueve variantes del otomí. Es importante mencionar que la variación dialectal se puede presentar incluso dentro de un mismo estado. Así, Lastra (2001) presenta tres variantes de otomí habladas en el Estado de México: el Otomí de Tilapa (Palancar, 2012; 2017), hablado en el municipio de Santiago Tianguistenco; el Otomí de Acazulco (Hernández-Green, 2015; 2018), del municipio de San Jerónimo Acazulco; y el Otomí de Toluca (Lastra, 1992), de San Andrés Cuexcontitlán.
Cada una de estas variantes muestra particularidades fonológicas, morfológicas, sintácticas y léxicas. En procesamiento del lenguaje natural (PLN), es importante trabajar con textos homogéneos o normalizados para obtener un mejor desempeño en los diversos métodos automáticos. Por ejemplo, una computadora puede tener problemas en asociar diferentes grafías o formas ortográficas que corresponden la misma palabra:
ɨhi/u̱hu/ʉhu/ụhu (venir)
En el otomí, como en diversas lenguas mexicanas, la variación ortográfica es grande. Esto responde, en parte, a las características lingüísticas propias de cada variante, pero también a cuestiones políticas, de alfabetización, falta de consenso en la norma ortográfica y a otros criterios, no necesariamente lingüísticos. Al procesar textos en otomí, encontramos que la escritura muestra diferentes variaciones dependiendo de la variante, la época, el autor, la fuente, etc.
Sistema fonológico
Relacionado con las diferentes variantes ortográficas, el otomí puede mostrar variación en su sistema fonológico. Principalmente se presentan variaciones es en el sistema vocálico. Si bien, todas las lenguas otomíes son tonales y distinguen entre vocales orales y vocales nasales, existen fonemas que pueden presentarse en unas variantes, mientras que en otras están ausentes. En general, las vocales orales incluyen a las mismas vocales que también se presentan en el español: a, e, i, o, u; pero su inventario de vocales orales no se limita a estas cinco. Es común, en todas las variantes, encontrar las vocales ɨ, ɛ y ə. En algunas variantes del estado de México, como son el Otomí de Temoaya (Andrews, 1949), el Otomí de Tilapa (Palancar, 2012: 2017) y el Otomí de Toluca (Lastra, 1992), se puede presentar la vocal ɔ. Además, en el Otomí de Temoaya y el de Toluca, se reporta la vocal ʌ.
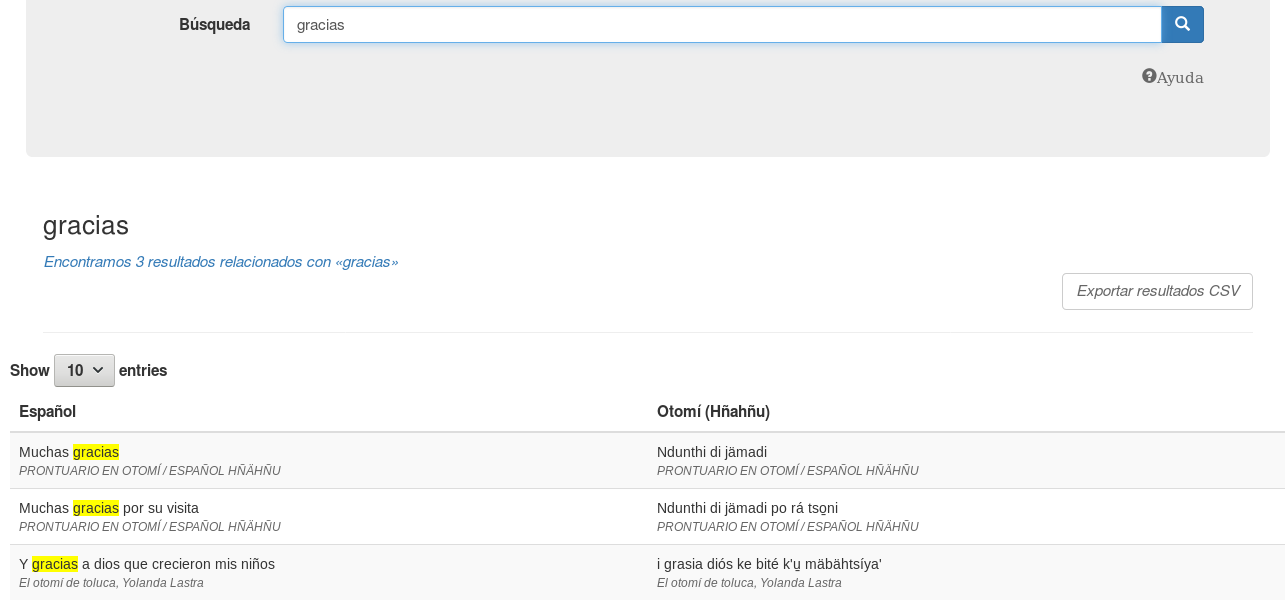
Como parte de nuestra investigación para conocer las variaciones en los textos en otomí, identificamos las diferentes vocales, y su escritura ortográfica, utilizadas en la mayor parte de las fuentes bibliográficas. La siguiente tabla muestra la representación de cada vocal en IPA (alfabeto fonético internacional), seguida de la ortografía práctica propuesta por el INALI (INALI, 2014) así como diferentes grafías utilizadas dependiendo de la fuente
IPA | Ortografía práctica | Hernández Cruz et al (2004) [Mezquital] | Hernández-Green (2015) [Acazulco] | Voigtlander y Echegoyen (1979) [de la Sierra] | Palancar (2017) [Tilapa] |
ɨ | u̱ | ụ | ụ | ʉ | u̱ |
ɛ | e̱ | ẹ | ẹ | ẹ | e̱ |
ɔ | a̱ | | ạ | | å |
ʌ | i̱
| | | | |
ɘ | o̱ | ọ | ọ | ø | ø |
Tabla 1. Escritura del sistema vocálico del otomí en diferentes estándares
Además de la variedad de vocales orales, las variantes otomíes muestran las vocales nasales ĩ, ũ, õ, ɛ̃, ɑ̃. Estas vocales nasales también muestran variación ortográfica. Por ejemplo, Andrews (1949) las denota con cedilla: i̧, u̧, o̧, ȩ, a̧. En la ortografía práctica, estas vocales se denotan por medio de diéresis: ï, ü, ö, ë, ä.
¿Qué escritura elegir?
Quizá esta sea una pregunta sin una respuesta única. Como lingüistas computacionales nos interesa minimizar la variación ortográfica de las diversas fuentes, en la medida de lo posible, para facilitar los métodos computacionales. Asimismo, es conveniente que los caracteres de la norma ortográfica sean fácilmente procesables por computadora, es decir, que sean parte de un formato de codificación de caracteres estándar (por ejemplo UTF-8 o Unicode).
La norma ortográfica que ha propuesto el INALI parece gozar de aceptación en diferentes medios de difusión. En Comunidad Elotl tenemos en marcha varios proyectos relacionados con el otomí, en la mayor parte de ellos hemos decidido realizar una normalización ortográfica de los textos tomando como referencia la norma práctica del INALI.
Sin embargo, es importante mencionar que en esta ortografía detectamos problemas de compatibilidad de los caracteres de las vocales: a̱, e̱, i̱, o̱, u̱. No es fácil encontrar estos caracteres en un estándar de codificación; ante esta dificultad, muchos de los que producen textos digitales en otomí optan por subrayar las vocales utilizando un editor de textos. Lo anterior resulta muy problemático para el procesamiento automático, pues el formato de subrayado se pierde al convertir los textos a un formato de texto plano (por ejemplo TXT). Por ahora, en la Tabla 1 ponemos disponibles las vocales subrayadas de esta norma utilizando el carácter asociado en UTF-8 (que hemos logrado encontrar hasta el momento).
Es importante que organismos, como el INALI, consideren los estándares de codificación, la facilidad y accesibilidad del conjunto de letras/caracteres digitales que eligen durante el proceso de constitución de una norma ortográfica.
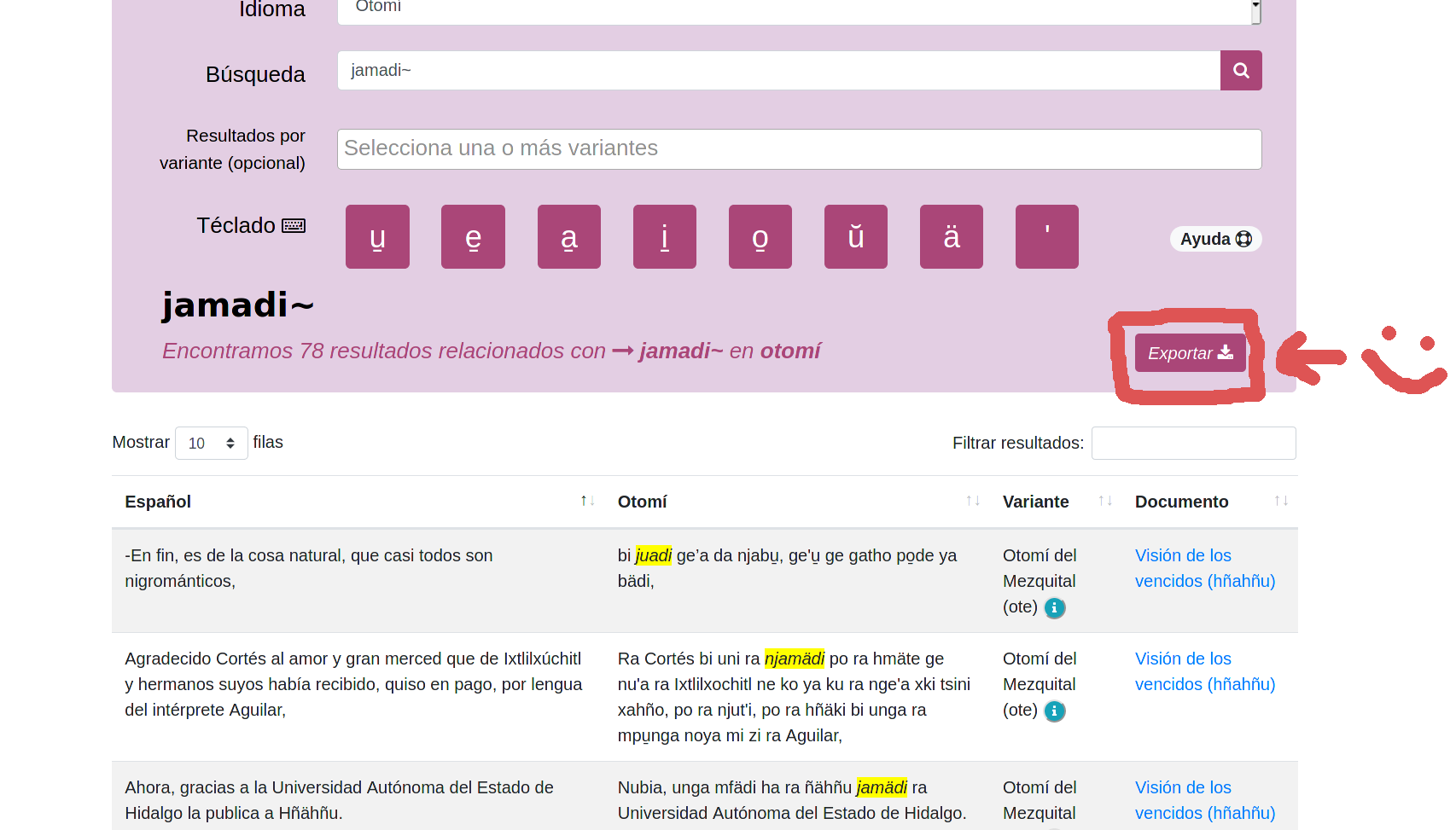
Nos gustaría despedirnos adelantando que en las próximas semanas daremos a conocer nuestro proyecto tsu̱nkwa, un corpus paralelo en línea español-otomí
* El término otomí usualmente abarca las diferentes designaciones que existen para esta lengua. Wright Carr (2005) reporta los siguientes nombres: ñatho (Toluca); ñahñu (Mezquital); ñañho (sur de Querétaro); n’yúhü (Sierra Madre Oriental). Sin embargo, existen todavía más designaciones, por ejemplo Palancar (2009) reporta el término ñöñhö para la región de San Ildefonso Tultepec, Querétaro, y Hernández-Green (2015) el de yühü para el de Acazulco.
Autores: Víctor Mijangos, Ximena Gutiérrez-Vasques
*Agradecemos a la estudiante de letras hispánicas, Yael Hermenegildo, por ayudarnos en nuestra búsqueda de caracteres digitales para el otomí
-Víctor es doctorante en lingüística por la UNAM y colaborador de Comunidad Elotl. Sus intereses abarcan la lingüística, las matemáticas y la lingüística computacional
-Ximena es doctora en Ciencias de la computación/ Lingüística computacional. Actualmente coordina la investigación y desarrollo dentro de la comunidad Elotl.
Referencias
Andrews, H. (1948). “Phonemes and morphophonemes of Temoaya Otomi”. En International Journal of American Linguistics, 15(1), pp. 213-222.
Hernández Cruz, L. & Victoria Torquemada, M. (2004). Diccionario del hñähñu (otomí) del Valle del Mezquital, estado de Hidalgo. México: Instituto Lingüístico del Verano.
Hernández-Green, N. (2015). Morfosintaxis verbal del otomí de Acazulco. Tesis doctoral. Doctorado en Lingüística Indoamericana, México: CIESAS.
Hermández-Green, N. (2018). “El sistema aspectual del Otomí de Acazulco”. En Cuadernos de Lingüística del Colegio de México, 5(2), pp. 280-334.
INALI. (2014). “njaua nt'ot'i ra hñähñu, norma de escritura de la lengua hñähñu (otomí) de los estados de Guanajuato, Hidalgo, Estado de México, Puebla, Querétaro, Tlaxcala, Michoacán y Veracruz”.
Lastra, Y. (1992). El Otomí de Toluca. México: Instituto de Investigaciones Antropológicas, UNAM.
Lastra, Y. (1996). "¿Es el otomı́ una lengua amenazada?" En Anales de antropologı́a, 33 (1), pp. 361-395.
Lastra, Y. (2001). Unidad y diversidad de la lengua. Relatos Otomíes. México: Instituto de Investigaciones Antropológicas, UNAM.
Palancar, E. L. (2009). Gramática y textos del hñöñö. Otomí de San Ildefonso, Tultepec, Querétaro. México: Universidad Autónoma de Querétaro.
Palancar, Enrique (2012). “The conjugation classes of Tilapa Otomi: An approach from canonical typology”. En Linguistics 50(4), pp. 783–832.
Palancar, E. L. (2018). “Clefts In Otomi: Extended Uses Of The Copular Construction”. En International Journal of American Linguistics, 84(1), 93-145.
Voigtlander, K. & Echegoyen, A. (1979). Luces contemporáneas del otomí; gramática del otomí de La Sierra. México: Instituto Lingüístico de Verano.Wright Carr, D. C. (2005), “Hñahñu, Nuhu, Nhato, Nuhmu. Precisiones sobre el término ‘otomí’”. En Arqueología Mexicana, 73, pp. 19-20.

 Se pueden realizar algunas personalizaciones como los colores de la página, colaboradorxs del proyecto, ligas a las redes sociales y el banner de la página (que por cierto modificamos para este ejemplo). La personalización la abordaremos a detalle en otra entrada ;)
Se pueden realizar algunas personalizaciones como los colores de la página, colaboradorxs del proyecto, ligas a las redes sociales y el banner de la página (que por cierto modificamos para este ejemplo). La personalización la abordaremos a detalle en otra entrada ;)
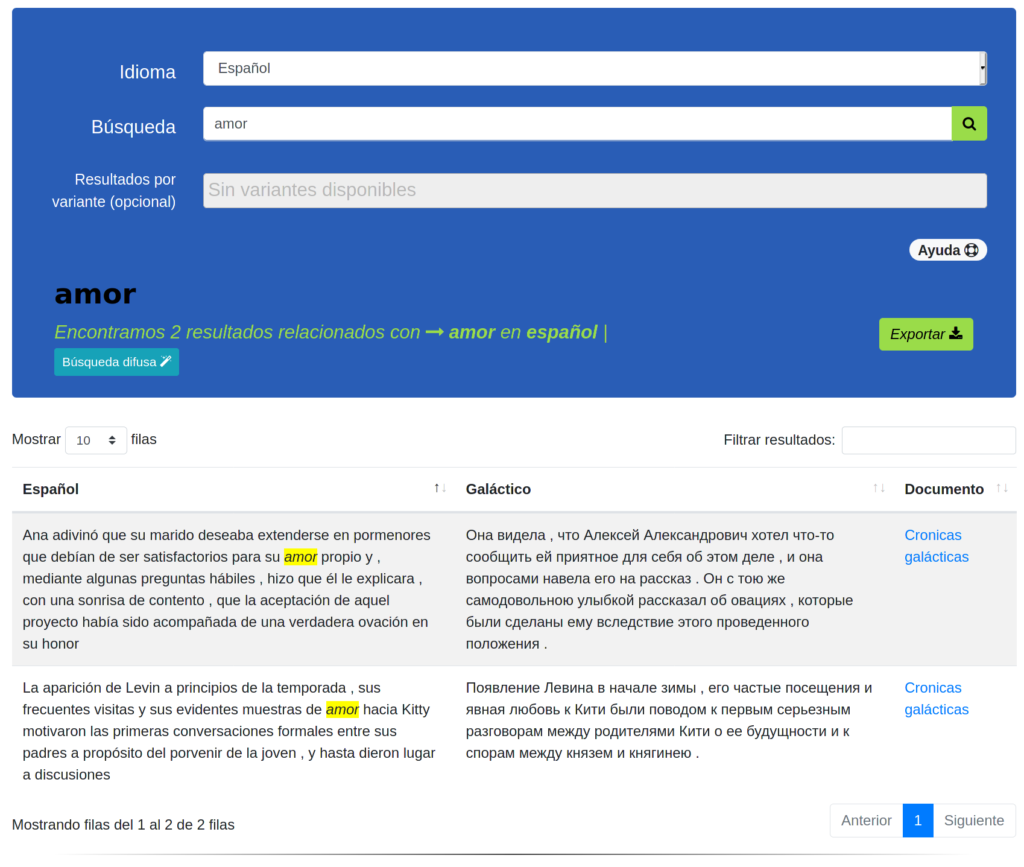
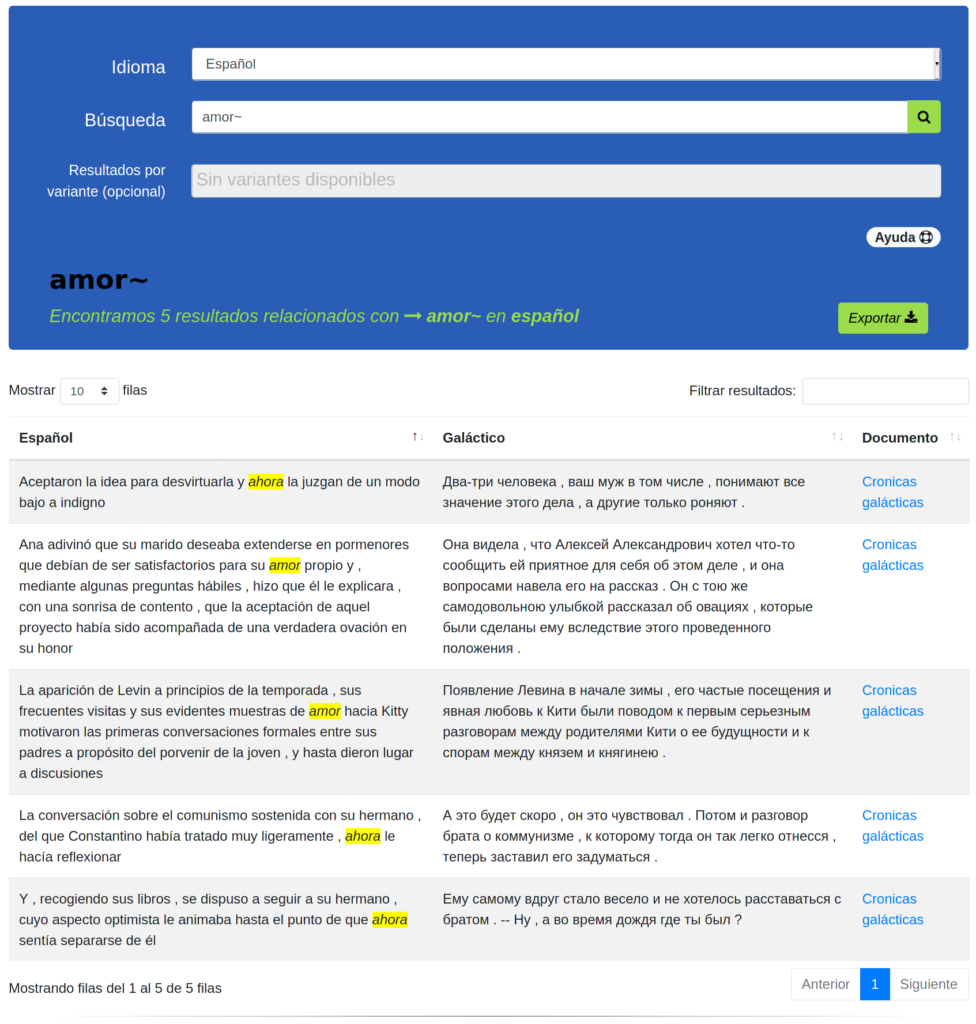
 Esto se ve triste porque nuestro sistema está vacío. Debemos alimentarlo con textos paralelos :book:.
Esto se ve triste porque nuestro sistema está vacío. Debemos alimentarlo con textos paralelos :book:.
 Damos clic en “Nuevo Documento”, agregamos el nombre del documento, el archivo
Damos clic en “Nuevo Documento”, agregamos el nombre del documento, el archivo 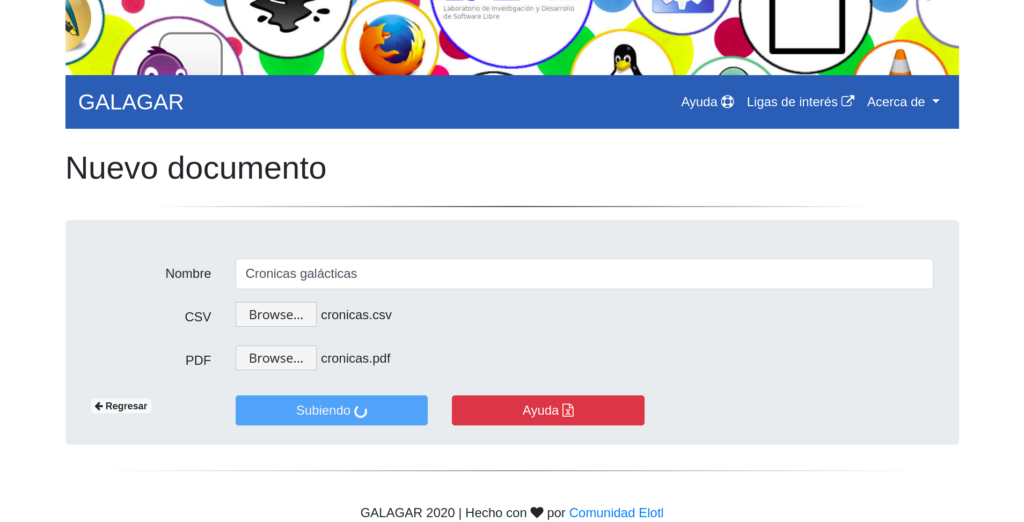






Recent Comments
No comments added yet.